
Preface
Speed and efficiency are critical for creating seamless user experiences. Whether you're streaming videos, shopping online, or using a real-time application, users demand instant responses. Distributed caching is a game-changer that makes applications faster and more efficient by minimizing delays. It ensures data is readily accessible. In this post, I’ll explore distributed caching, discussing what it is, why it’s vital, how you can use it to improve your applications, and the specific ways Grafana benefits from it.
What is Distributed Caching?
Distributed caching is like having a bunch of mini-libraries around the globe where your application can grab data instantly. Instead of one big library that everyone has to visit, there are many smaller ones, so no matter where you are, the information you need is close by. This setup makes your application run smoother, quicker, and keeps it from crashing under pressure, which is super important for applications that need to work fast and reliably.
Different Types of Caching
Caching can be broadly categorized into two types: local caching and distributed caching.
Local Caching
Local caching stores data on the same server where the application is running. It's like having a mini-library in your room where you can quickly grab a book without going to the main library. Local caching is great for small applications or when you need to store data temporarily.

Distributed Caching
Distributed caching stores data across multiple servers, making it accessible from anywhere. It's like having mini-libraries in different cities, distributed geographically, so no matter where you are, you can grab a book quickly. Distributed caching is ideal for large applications or when you need to store data permanently.

Why Do We Need Distributed Caching?
Challenges with Local Caching in Distributed Systems
Local caching, while effective for single-machine applications, faces limitations in distributed systems. As applications scale and serve users from various locations, relying solely on local caching can lead to data inconsistencies, increased latency, and potential bottlenecks. For instance, if one server updates its local cache but other servers remain unaware of this change, users might receive outdated data.
Benefits of Distributed Caching
Distributed caching addresses the limitations of local caching by storing data across multiple machines or nodes in a network. This approach offers several advantages:
- Scalability: As traffic to an application grows, additional cache servers can be added to the distributed cache system without disrupting existing operations.
- Fault tolerance: If one cache server fails, requests can be rerouted to another server, ensuring continuous availability of cached data.
- Performance: Data is stored closer to the user, reducing the time taken to fetch it and improving response times.
Example of the Benefits of Distributed Caching
Think of a global online retailer as a worldwide library system. If this retailer only relies on local caching, it's like having all the books in one central library in North America. Customers in Asia would face long waits for information, much like waiting for a book to travel across the globe. But with distributed caching, it’s as if the retailer has set up mini-libraries in strategic locations like Asia, North America, and other regions. Now, when someone in Asia wants to learn about a product, they don't need to wait for information to come from far away; they can simply visit their local mini-library (cache server) to instantly access the book (data) they need. This ensures that every customer, regardless of where they are, experiences fast and efficient service, as if they're browsing in their very own local library.
Key Components of Distributed Caching
Cache servers and their roles
Cache servers are the primary components in a distributed caching system. They store temporary data across multiple machines or nodes, ensuring that the data is available close to where it’s needed. Each cache server can operate independently, and in case of a server failure, the system can reroute requests to another server, ensuring high availability and fault tolerance.
Data partitioning and replication strategies
In distributed caching, data is partitioned across multiple cache servers to ensure efficient data distribution and retrieval. There are several strategies for data partitioning:
- Consistent hashing: This method ensures that data is evenly distributed across cache servers and minimizes data movement when new servers are added or existing ones are removed.
- Virtual nodes: Virtual nodes are used to handle scenarios where cache servers have varying capacities. They ensure that data distribution remains balanced even if some servers have higher storage capacities than others.
Replication is another crucial aspect of distributed caching. By replicating data across multiple cache servers, the system ensures data availability even if a server fails. Common replication strategies include master-slave replication, where one server acts as the master and others as replicas, and peer-to-peer replication, where each server acts both as a primary store and a replica for different data items.
Example of Data Partitioning and Replication
Imagine our global online retailer example as a network of libraries around the world, each storing different products like books of various genres. When a customer looks for a product, the system smartly sends them to their local library (server) using consistent hashing. If one library faces issues, there are copies of the product data in other libraries, ensuring customers can always find what they need, just like having backup books in nearby libraries.
Popular Distributed Caching Solutions
Memcached
Memcached is a general-purpose distributed memory caching system. It is designed to speed up dynamic web applications by reducing database load. Memcached is simple yet powerful, supporting a large number of simultaneous connections and offering a straightforward key-value storage mechanism.
Redis
Redis is an open-source, in-memory data structure store that can be used as a distributed cache , database, and message broker. It supports various data structures such as strings, hashes, lists, and sets. Redis is known for its high performance, scalability, and support for data replication and persistence.
Hazelcast
Hazelcast is an in-memory data grid that offers distributed caching, messaging, and computing. It provides features like data replication, partitioning, and native memory storage. Hazelcast is designed for cloud-native architectures and can be easily integrated with popular cloud platforms.
Apache Ignite
Apache Ignite is an in-memory computing platform that provides distributed caching, data processing, and ACID-compliant transactions. It can be used as a distributed cache, database, and message broker. Apache Ignite supports data replication, persistence, and querying capabilities.
Implementing Distributed Caching with Redis in Golang
package main
import (
books "github.com/mdshahjahanmiah/distributed-caching/pkg/book"
"github.com/mdshahjahanmiah/distributed-caching/pkg/cache"
"github.com/mdshahjahanmiah/distributed-caching/pkg/config"
"github.com/mdshahjahanmiah/explore-go/logging"
"log/slog"
)
func main() {
conf, err := config.Load()
if err != nil {
slog.Error("failed to load configuration", "err", err)
return
}
logger, err := logging.NewLogger(conf.LoggerConfig)
if err != nil {
slog.Error("initializing logger", "err", err)
return
}
// Initialize Redis nodes with consistent hashing
cache.InitializeNodes()
defer cache.Cleanup()
bookService := books.NewBookService(logger)
// Fetch book details considering user region
bookKey := "book::1984"
bookDetails, err := bookService.FetchBookDetails(bookKey, "Europe")
if err != nil {
logger.Fatal("Failed to fetch book details", "err", err)
}
logger.Info("Fetched book details", "book_details", bookDetails)
}
For the full code, please visit gitHub repository, Understanding Distributed Caching
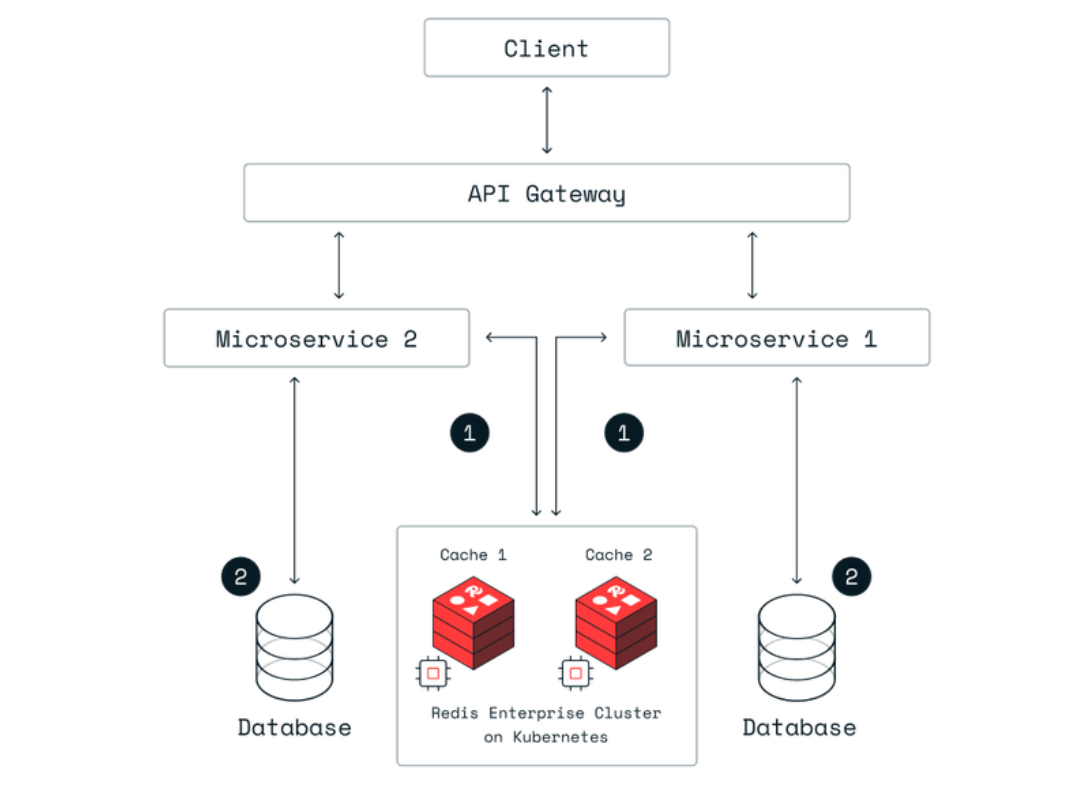
How Grafana Benefits from Distributed Caching
Grafana is renowned for its ability to create interactive dashboards for monitoring and visualization, pulling data from various sources. To manage the high volume of data requests and ensure a seamless user experience, Grafana employs distributed caching. This strategy significantly enhances performance, scalability, and user satisfaction.
Speeding Up Dashboard Load Times
Query Caching
Grafana caches the results of queries, meaning if a dashboard or panel is queried multiple times, the data can be fetched from the cache rather than from the original data source each time. This reduces dashboard load times, making the experience smoother for users, especially those dealing with complex queries or dashboards with many panels.
Example:
Imagine a dashboard showing real-time metrics from multiple databases. With distributed caching, the initial query might take longer, but subsequent refreshes are almost instantaneous, as data is pulled from a nearby cache server.
Reducing Load on Data Sources
Lower API Calls
By caching query results, Grafana minimizes the number of direct calls to data sources. This not only speeds up data retrieval but also reduces the strain on backend systems, potentially saving on API costs or preventing throttling by external services.
Use Case
For organizations utilizing cloud-based services like AWS CloudWatch or Azure Monitor, caching can significantly decrease costs associated with API usage limits.
Enhancing User Experience Across Geographies
Geographical Distribution
With distributed caching, data can be stored closer to where users are located. This geographical distribution of cache nodes means users in Europe, Asia, or the Americas experience similar performance, regardless of where the primary data source is located.
Scenario
A global company uses Grafana to monitor their infrastructure. Distributed caching ensures that an engineer in Tokyo has the same fast access to dashboard data as one in New York, without needing to wait for data to travel across continents.
Handling High Concurrency
Scalability
Distributed caching allows Grafana to handle thousands of simultaneous users without degrading performance. Each cache node can independently serve data, balancing the load across the infrastructure.
High-Traffic Events
During peak usage times, like a major product launch or a system-wide incident, distributed caching prevents server overload, keeping dashboards responsive.
Data Consistency and Freshness
Cache Invalidation
Grafana implements strategies like TTL (Time To Live) for cached data, ensuring that while performance is enhanced, data does not become outdated. Users can control how long data remains cached before refreshing from the source.
Real-Time Monitoring
For scenarios where real-time data is crucial, Grafana can be configured to bypass or refresh the cache more frequently, balancing performance with data currency.
Conclusion
In conclusion, distributed caching stands out as an essential technique for modern applications, offering speed, scalability, and the ability to manage real-time data efficiently. By distributing data across multiple servers, it not only alleviates the burden on primary data sources but also ensures quick data access, enhancing user experience while accommodating the needs of applications that span across global landscapes.
NOTE: I'm constantly delighted to receive feedback. Whether you spot an error, have a suggestion for improvement, or just want to share your thoughts, please don't hesitate to comment/reach out. I truly value connecting with readers!