![]()
Preface
Microservice architecture is gaining popularity for building large systems, but a common challenge is managing distributed transactions across multiple microservices.
While distributed transactions are important to microservices, they are often misunderstood. In this article, I look to iron out these misunderstandings. I'll share my project experience, the actual problem, potential solutions, and explain it in the simplest way possible.
What are distributed transactions?
A transaction is like a series of steps or actions that need to happen together. Transactions provide the illusion that either all the operations within a series or group complete successfully or none of them do, as if the series or group were a single atomic operation.
If an application only updates data within one database, incorporating changes into a transaction is simple.
How centralized, non-distributed databases implement transactions (ACID)
A transaction with the correct behaviour must exhibit the following, also known as the ACID properties:
Atomicity
Either all writes in the transaction succeed or none, even in the presence of failures.
Consistency
It ensures that transactions bring the database from one consistent state to another consistent state.
Isolation
It ensures that transactions operate independently of each other
Durability
Committed writes must be permanent.
Why do we need distributed transactions?
Let's consider transferring funds from your bank account to a friend's account, but the operation fails due to a network partition, causing communication interruption. In this scenario, your account is debited, but your friend's account is not credited yet. We need to put the debited amount back into your account. It's all about ensuring either both the debit and credit operations succeed together or neither of them happens. This is where transactions come in, ensuring actions like withdrawals and deposits into one transaction.
If you have only one database, you wouldn't typically need to deal with distributed transactions in the traditional sense, If deposit and withdrawal operations are handled by separate microservices, each with its own datastore, then you might need distributed transactions to ensure consistency between the two microservices.
However, even with a single database, there are scenarios where transactional integrity is crucial.
Multiple tables
Even if you're using just one database, transactions may still involve multiple tables. For example, updating data in one table based on changes in another. In these cases, transactions ensure that changes are atomic and consistent.
Concurrency control
In multi-user environments such as shared bank account, concurrent transactions may occur. Transactions need to be isolated from each other to prevent interference. For example, if two users attempt to update the same record simultaneously, you want to ensure that one transaction completes before the other starts to maintain data integrity.
Error handling
Even with a single database, errors can occur during transactions (e.g., deadlock, constraint violations). Handling these errors gracefully is essential to maintain data consistency and application reliability.
So Distributed transactions aren't only relevant in the context of multiple databases, transactional management within a single database remains essential for ensuring data consistency, concurrency control, and error handling.
In a hypothetical scenario, We now recognize that distributed transactions aren't exclusive to distributed systems. Even monolithic applications can encounter situations where distributed transactions are a part of our daily routine.
Solution Patterns for Distributed Transactions
Now that we've identified a scenario requiring distributed transactions, let's explore some common solutions people use to address these challenges.The solution will be tailored to our specific problem domain, determining whether we require synchronous distributed transactions or asynchronous distributed transactions.
Let's begin with a more conventional perspective with banking application in accordance with monolithic application and non shards' database. When a user Sas transfers money to the user Ilia, we need to ensure the following steps:-
Monolithic application and non-shard database
- Upon successful completion, user Ilia's account is credited and user Sas's account is debited.
- If the database server crashes after completion of transaction, it must revert to its state before the transaction.
- Transaction failure, such as due to insufficient balance for user Sas, should prevent updating both users' accounts.
- After the transaction, the database must ensure consistency, ensuring user Ilia's account isn't credited without a user Sas account being debited.
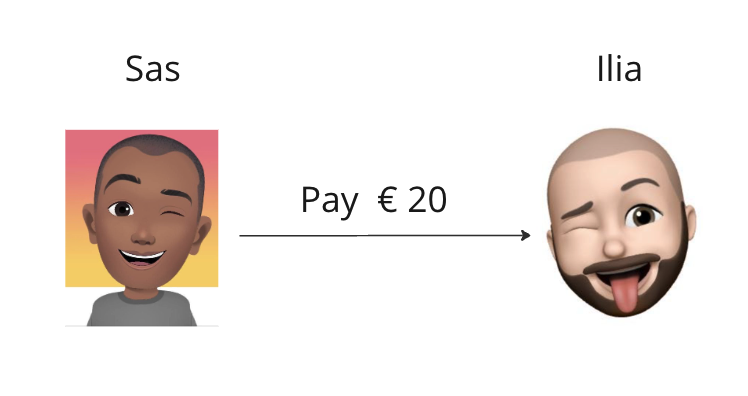
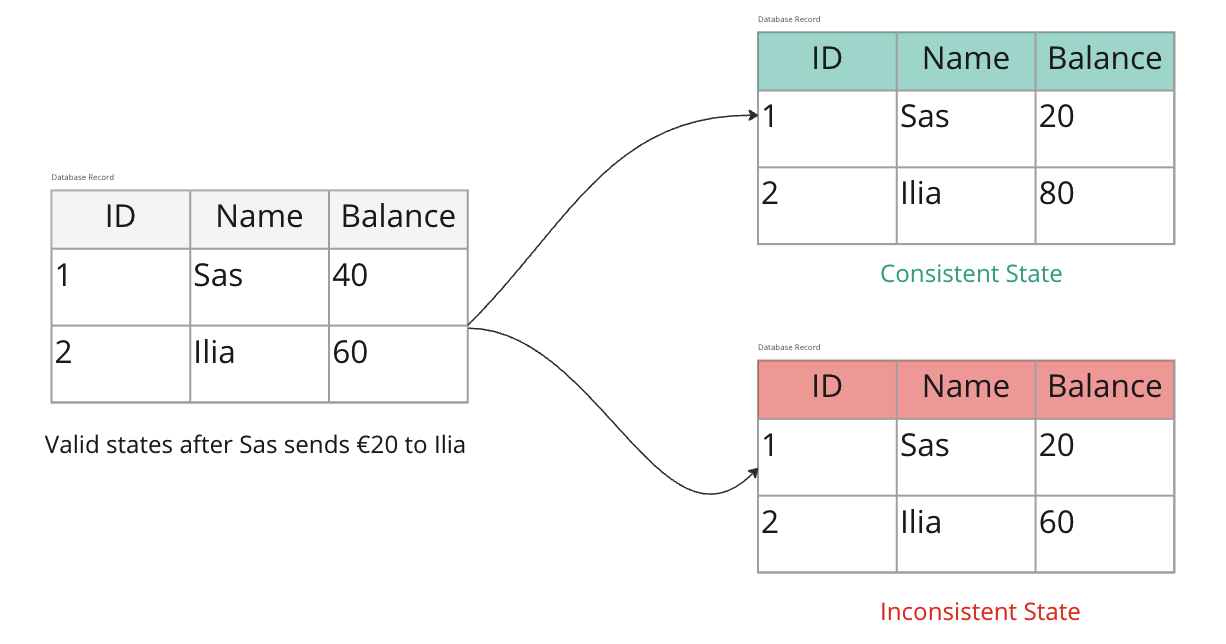
Possible states after user Sas sends 20€ to user Ilia.
For the above example, the database transaction will consist of the following statements :
Begin
update set balance = balance + 20 where user = ‘Ilia’;
update set balance = balance - 20 where user = ‘Sas’;
CommitAssume that the initial balance of user Sas and Ilia are 40€ & 60€ respectively. Following are the possibilities while executing the above transaction: -
- Success - In this case, the transaction will be committed. User Sas's balance will be 20 € & user Ilia's balance will be 80€. If the database crashes after this, it will come back to this same state after recovery.
- Failure - If there is a failure while updating the user Sas's balance, the database will abort the transaction. And it will roll back all the changes. The user’s balance won’t be affected.
Monolithic application and shard's database
We have now decided to scale our database, to cater to increasing customers. Data is distributed across multiple database servers. So, user Sas and user Ilia’s database records may fall in different shards.
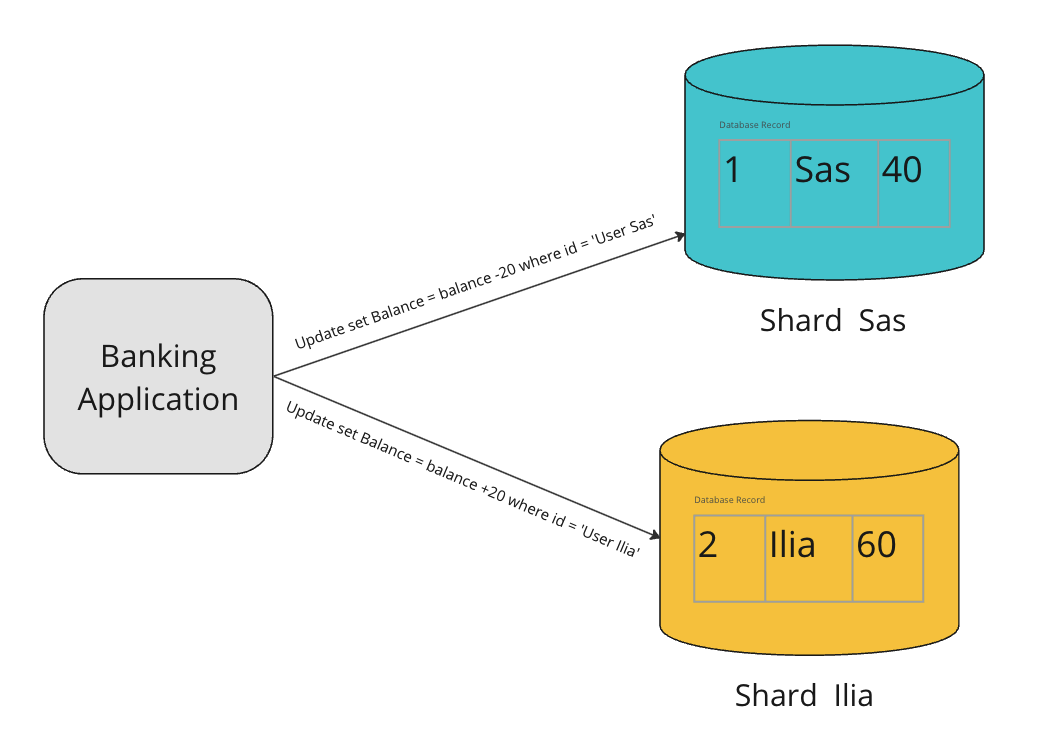
Can we still guarantee atomicity in the case of sharded databases? No, since only a single database server guarantees atomicity. While dealing with many database servers, it’s the application’s responsibility to make a transaction atomic. We will see what are the different error scenarios that we need to tackle. We have to ensure that either the transaction completes successfully or fails. We don’t want to leave the transaction midway in an inconsistent state. 2-Phase Commit makes distributed transactions atomic in nature.
Synchronous Distributed Transactions
A synchronous distributed transaction involves multiple participants such as deposit, withdraw service or components (Transaction Participants) across a network. It means all operations are executed in real-time, coordinating (Transaction Coordinator) each step's completion before proceeding to the next, ensuring transactional consistency and atomicity.
Two-Phase Commit Protocol (2PC):
The two-phase commit (2PC) protocol is a distributed algorithm that coordinates all the processes that participate in a distributed transaction on whether to commit or abort (roll back) the transaction.
Phases
Two-phase commit consists of the following phases:
- Prepare phase: The prepare phase involves the coordinator node collecting consensus from each of the participant nodes. The transaction will be aborted unless each of the nodes responds that they're prepared.
- Commit phase: If all participants respond to the coordinator that they are prepared, then the coordinator asks all the nodes to commit the transaction.
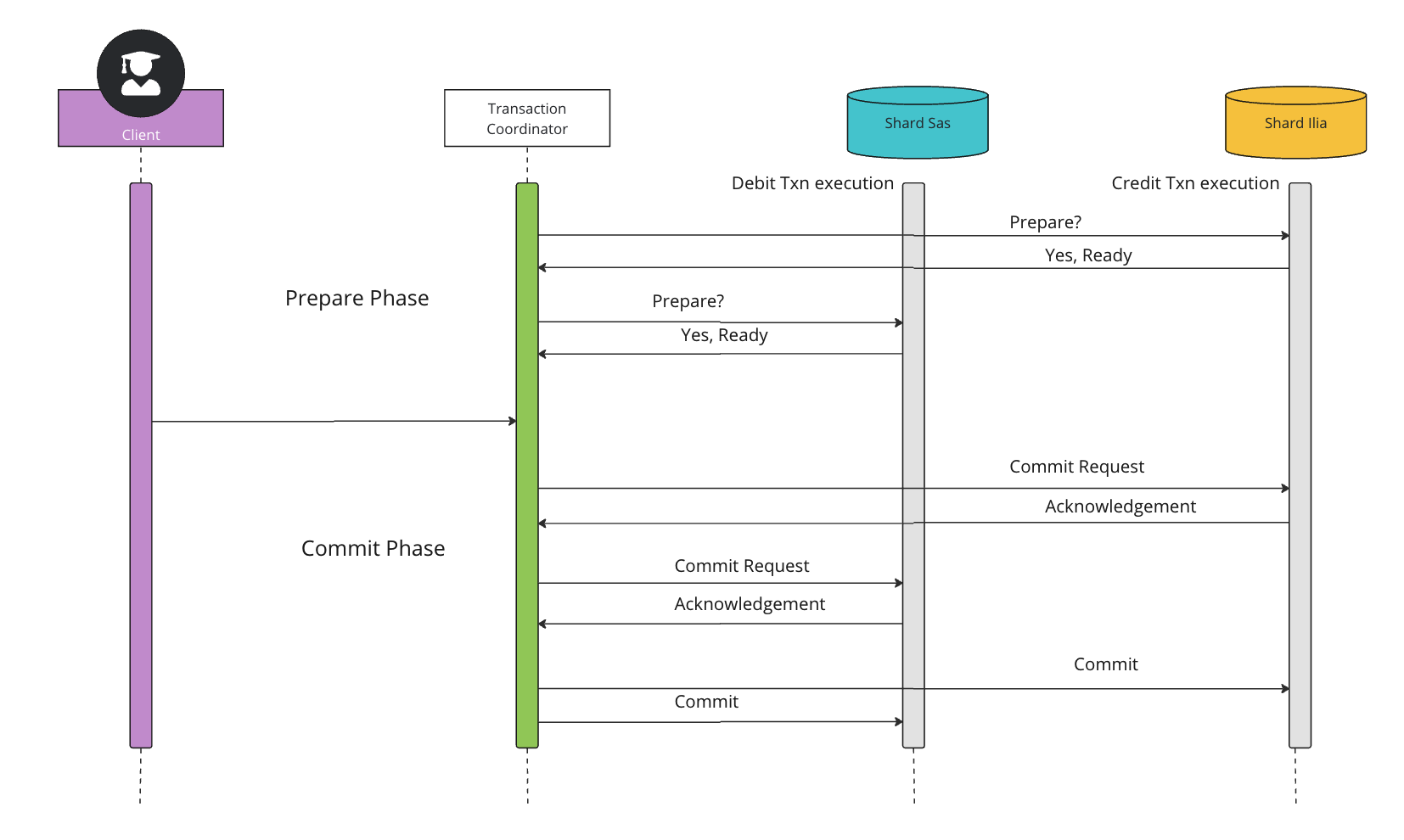
If a failure occurs, the transaction will be rolled back.
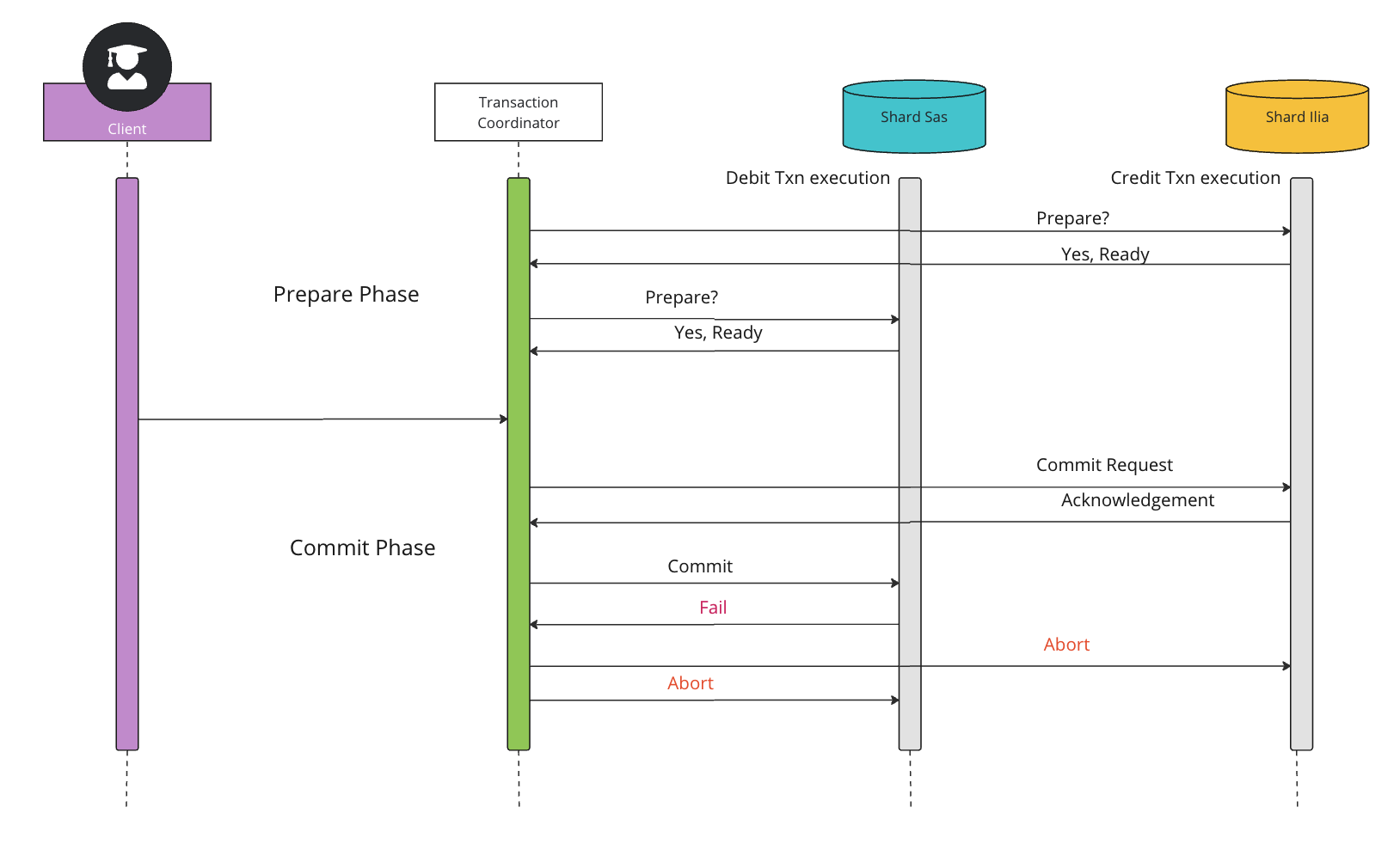
Drawbacks of 2-Phase Commit
The major downside of the two-phase commit protocol is if the coordinator fails before it can broadcast the outcome to the participants, the participants may get stuck in a waiting state.
- What if one of the nodes crashes?
- What if the coordinator itself crashes?
- It is a blocking protocol.
Three-Phase Commit Protocol (3PC):
Three-phase commit (3PC) is an extension of the two-phase commit where the commit phase is split into two phases to mitigate the problems of node crashes, coordinator crash, and aming to reduce 2PC's blocking nature.
Phases
Three-phase commit consists of the following phases:
- Prepare phase: This phase is the same as the two-phase commit.
- Pre-Commit phase: Coordinator issues the pre-commit message and all the participating nodes must acknowledge it. If a participant fails to receive this message in time, then the transaction is aborted.
- Commit phase: This step is also similar to the two-phase commit protocol.
Why is the pre-commit phase helpful?
The pre-commit phase accomplishes the following:
- If the participant nodes are found in this phase, that means that every participant has completed the first phase. The completion of prepare phase is guaranteed.
- Every phase can now time out and avoid indefinite waits.
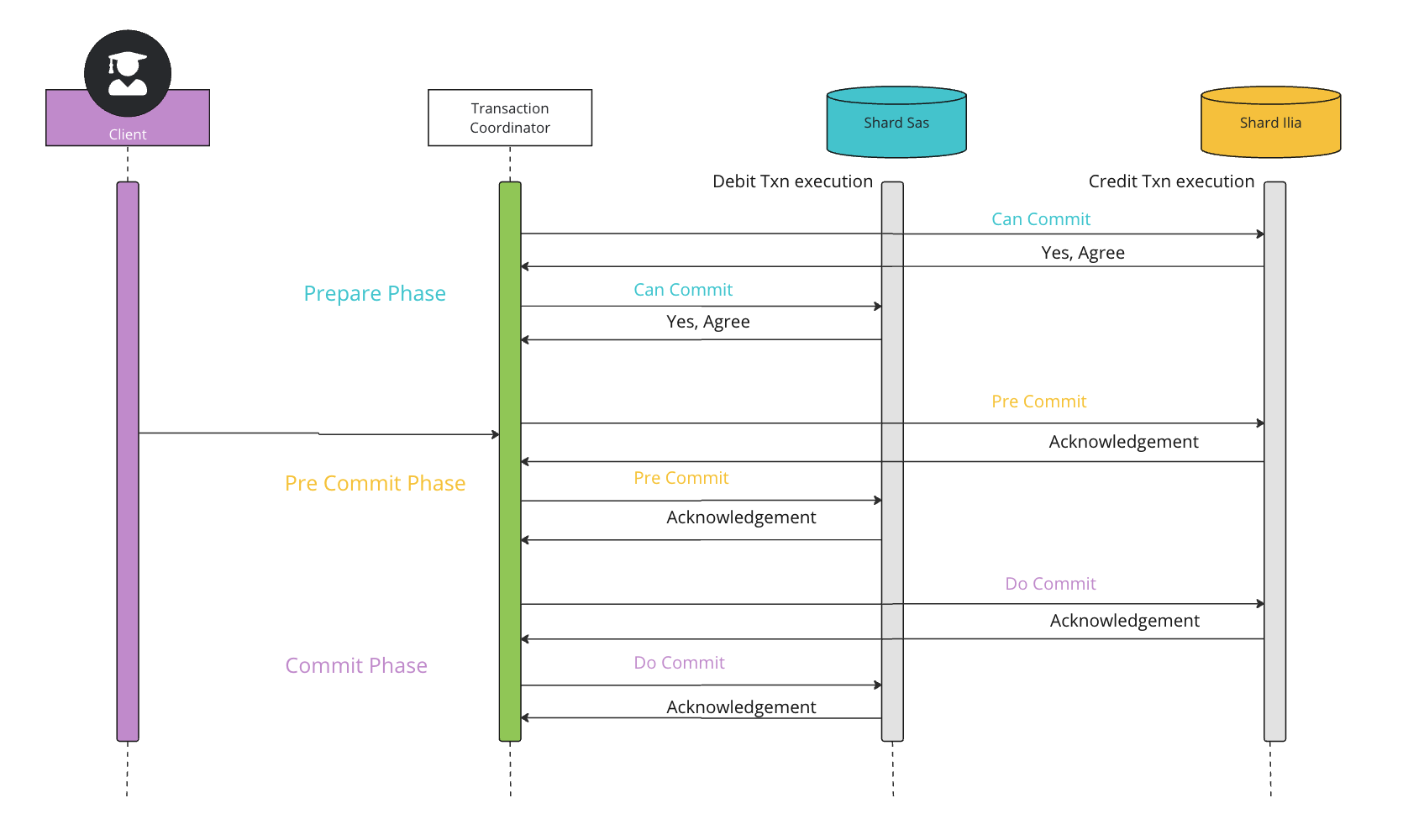
Drawbacks of 3-Phase Commit
Although the three-phase commit (3PC) protocol addresses some drawbacks of the two-phase commit (2PC) protocol, it has its own limitations:
- Complexity: It involves an additional phase. This increased complexity can make implementation and understanding more challenging.
- Increased Message Overhead: With an extra phase comes increased message exchange between nodes, leading to higher network overhead. This can impact performance, especially in large-scale distributed systems or environments with high latency.
- Potential for Deadlocks: The additional phase in 3PC introduces the possibility of deadlocks in certain scenarios, where nodes might become deadlocked waiting for messages or acknowledgments from each other.
Asynchronous Distributed Transactions
We've discovered that using protocols like 2PC or 3PC for distributed transactions might not be the best fit for microservices. That's because they rely on synchronous communication, which can slow things down. Instead, we might opt for an asynchronous distributed transaction. In this setup, each part of the transaction can do its job without waiting for the others, communicating the results later on.
Furthermore, Commit Protocols like 2PC or 3PC are not supported by many modern-day message brokers such as RabitMQ and Apache Kafka. In addition to that, some of the popular databases such as MongoDB and Cassandra are also not supported.
Sagas
A Saga is a sequence of local transactions. Each local transaction updates the local database using the familiar ACID transaction frameworks and publishes an event to trigger the next local transaction in the Saga. If a local transaction fails, then the Saga executes a series of compensating transactions that undo the changes, which were completed by the preceding local transactions.
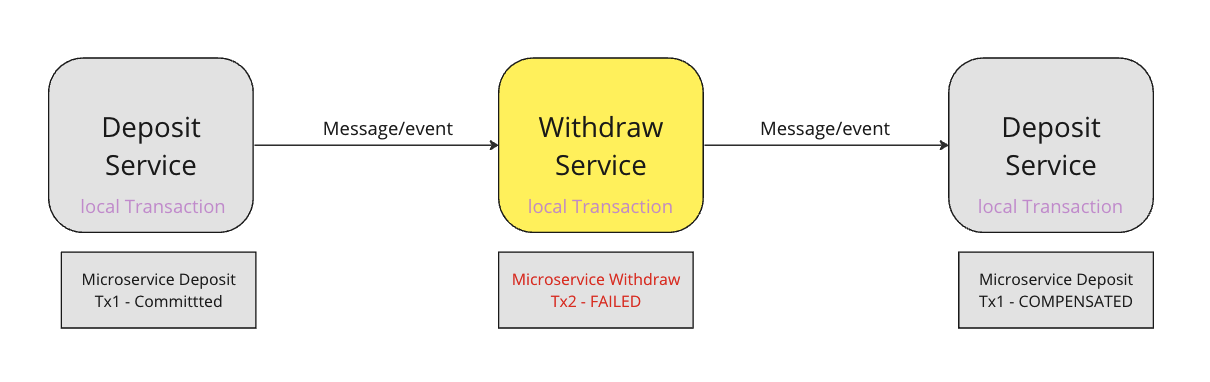
It is an asynchronous and eventually consistent transactional approach, which is quite analogous to a typical microservices application architecture, where a distributed transaction is fulfilled by a set of asynchronous transactions on related microservices.
Saga Coordination
Sagas can be implemented in “two ways” primarily based on the logic that coordinates the steps of the Saga.
- Choreography-based sagas
- Orchestration-based sagas
Choreography-based sagas
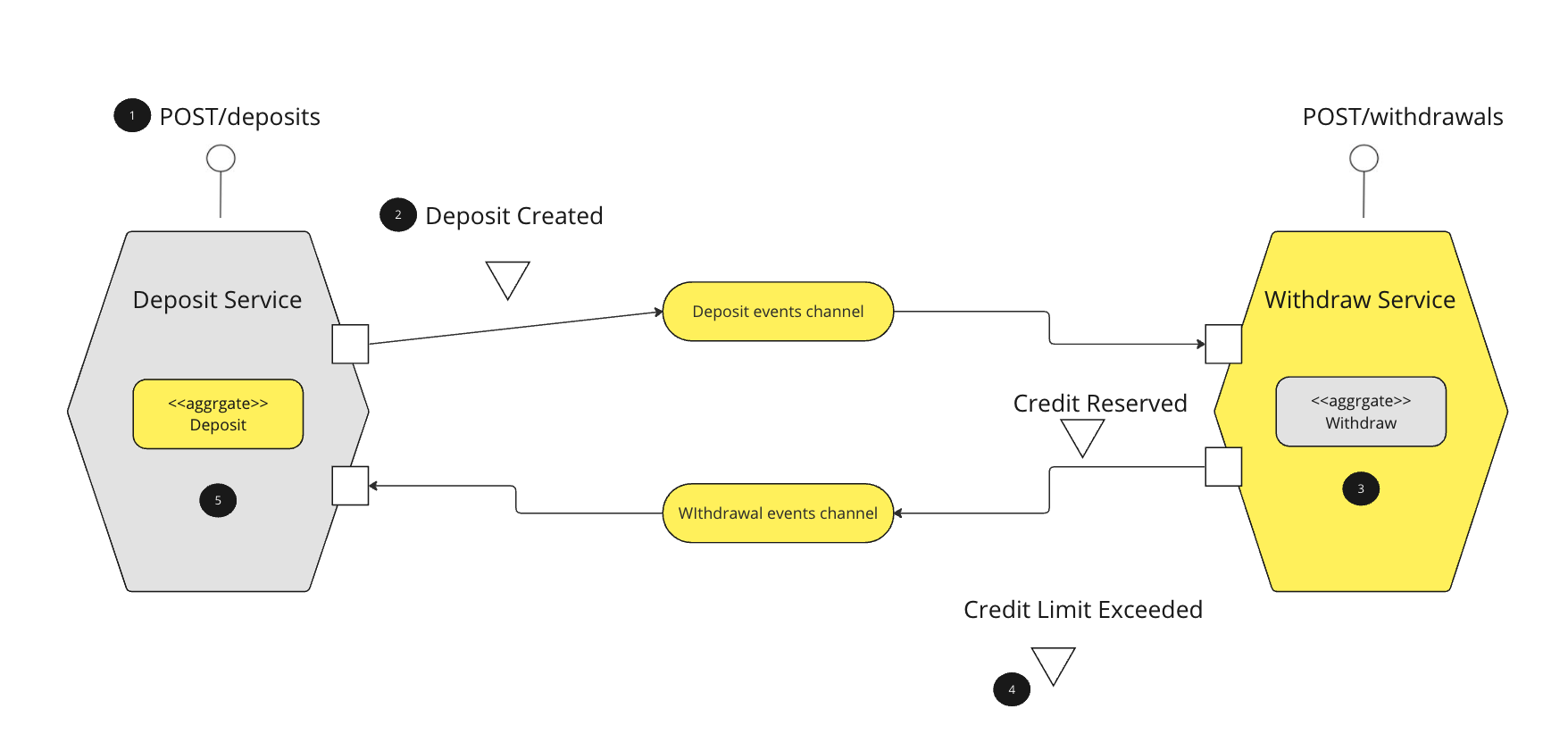
In this approach, unlike orchestrator-based saga, there is no central coordinator to tell saga participants what to do. Saga participants subscribe to each other’s events and respond accordingly. A banking application that uses this approach would create a deposit using a choreography-based saga that consists of the following steps:
- The
Deposit Servicereceives thePOST /depositsrequest and creates a Deposit in aPENDINGstate - It then emits a
Deposit Createdevent - The
Withdrawal Serviceevent handler attempts to reserve credit - It then emits an event indicating the outcome
- The
DepositService’sevent handler either approves or rejects theDepositService
Orchestration-based sagas
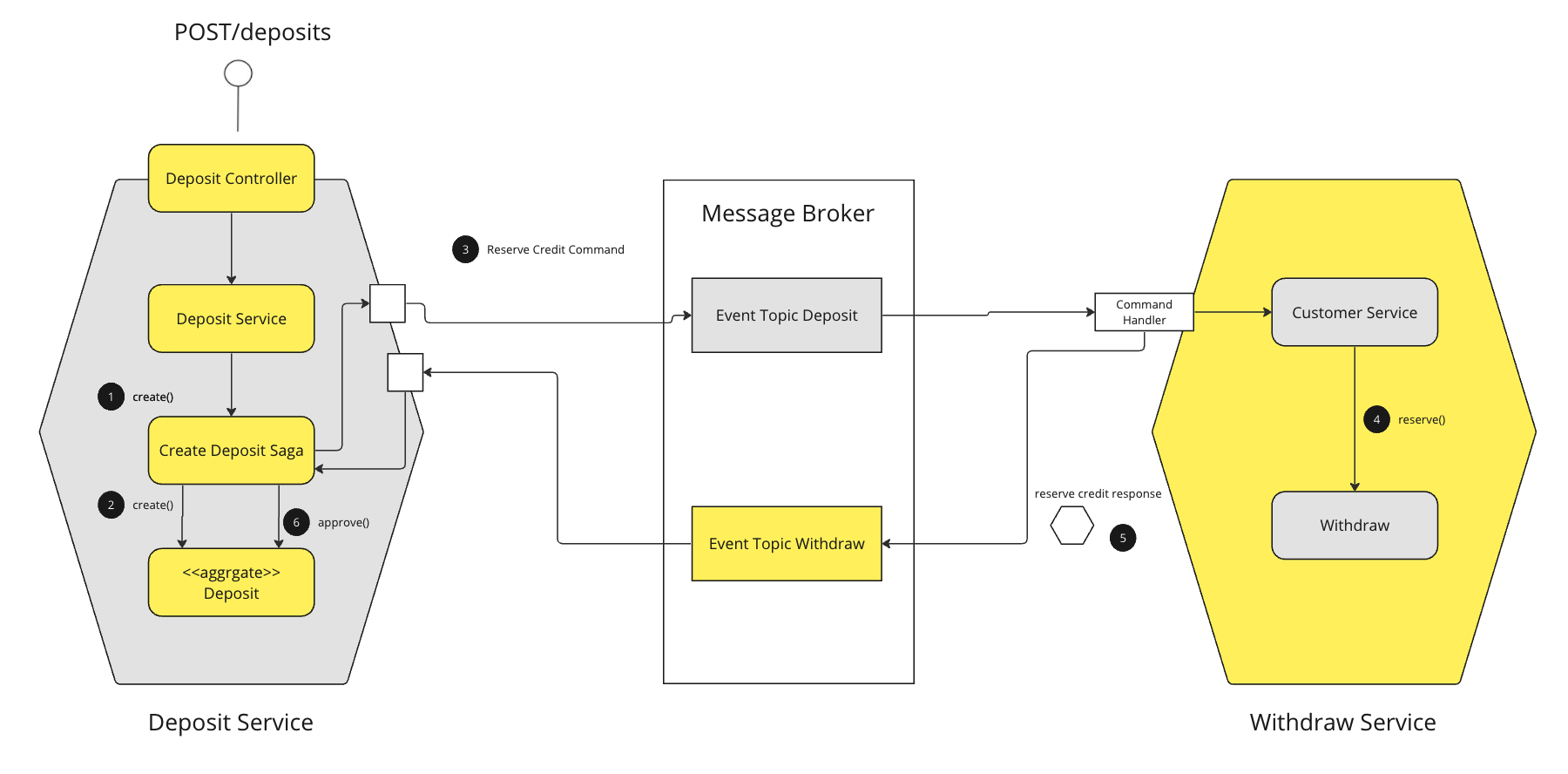
In this type, a central Saga orchestration class is responsible to tell saga participants what to do. An e-commerce/banking application that uses this approach would create a deposit using an orchestration-based saga that consists of the following steps:
- The
Deposit Servicereceives thePOST /depositsrequest and creates theCreate Depositsaga orchestrator - The saga orchestrator creates a
Depositin thePENDING state - It then sends a
Reserve Creditcommand to theWithdrawal Service - The
Customer Serviceattempts to reserve credit - It then sends back a reply message indicating the outcome
- The saga orchestrator either approves or rejects the
deposit
Drawbacks of Sagas
- Limit business logic in the saga orchestrator for a cleaner architecture. Keep business logic in relevant services, not in the orchestrator.
- Less Isolation — Microservice architecture lacks isolation compared to traditional ACID transactions because saga participants commit changes locally before completing the entire transaction, leading to potential database anomalies.
Anomalies
There are three types of anomalies found in a typical saga.- Lost Updates — One saga overwrites an update made by another saga.
- Dirty Reads — One saga reads data that is in the middle of being updated by another saga.
- Fuzzy / Non-repeatable Reads — Two different sets of a saga read the same data and get different results because another saga has made updates.
Out of these three, lost update and dirty read scenarios are the most common. To address anomalies, implementing countermeasures in your designs is necessary. Various countermeasure approaches exist in the literature, with some key ones outlined below.
- Semantic Lock - In sagas, an application-level lock uses flags to mark records created or updated by compensatable transactions. These flags signal potential changes and can be cleared by retriable or compensating transactions.
- Commutative Updates — Designing the system for more commutative update operations ensures orderly updates, minimizing lost updates.
- Pessimistic View — Reordering saga participants/services to minimize the effect of dirty reads.
- Reread Values — This countermeasure reread values before updating it to further to re-verify the values are unchanged during the process. This will minimize lost updates.
- By Value — This strategy will select concurrency mechanisms based on the business risk. This can help to execute low-risk requests using sagas and execute high-risk requests using distributed transactions.
Conclusion
That’s it! Hope you got some good insight into the distributed transactions and other related concepts by reading this post. In exploring distributed transactions for microservices, it's clear that synchronous protocols like 2PC and 3PC pose challenges due to their blocking nature, prompting the need for asynchronous distributed transactions.
NOTE: I'm constantly delighted to receive feedback. Whether you spot an error, have a suggestion for improvement, or just want to share your thoughts, please don't hesitate to comment/reach out. I truly value connecting with readers!